




The article covers why we need coroutines, it’s fundamental blocks in theory, and then shows them in action (code) to explain the blocks clearly.
Kotlin introduced Coroutines for asynchronous programming and more. This article covers why we need Kotlin Coroutines, it’s fundamental building blocks in theory, and then shows them in action (code) to explain the blocks clearly.
The code shown is available on Github as well.
Why do we need coroutines?
Apps perform various tasks. For each of this task, operation time varies. While doing these time varying tasks, we need to ensure user experience isn’t degraded. One way to do that (while also reducing bottlenecks) is to do asynchronous operations.
Let’s discuss potential solutions to do this and their potential problems:
- Threading — It is a great solution. But managing them can quickly get out of hand.
- Callbacks — Simple, obvious and easy to implement but can quickly degrades down to callback hell.
- Futures and promises — Personally I haven’t used them a lot, but I find them not powerful enough for my use-cases.
- Reactive (Rx) streams — Powerful solution but introduces drastic change in way of thinking.
- Coroutines — Elegant solution. Offers a small learning curve in comparison to other solutions, minimal change to code and looks the same as synchronous code.
Let’s begin our understanding of coroutines.
Coroutines are suspendible execution blocks
Don’t worry. I’ll explain these keywords later. In simple words — they are lightweight threads so you can create millions of them and they will run and execute on a shared pool of threads easily.
Note: They aren’t bundled with the Kotlin langauge but is instead packaged as a library by Jetbrains. So from here on when I say library, I mean the coroutine library.
Basic keywords and building blocks

The best way to explain all the required keywords is through an example. So let’s take one. Suppose we have a task T in which we need to combine values from 5 other long running child tasks — T1, T2, T3, T4, T5.
T is a fire and forget kind of task — the invoking page doesn’t care about it’s result and the task must be completed even if the page closes. T1, T2, T3 are network calls, T2 depends on T1 and T3 on T2. T4 is a file read and T5 is a database entry operation which depends on T4. We’ll call the coroutine used to do the task T as C and C1, C2, C3, C4, C5 for child tasks respectively.
Now before we dive into the code, we need to learn a little bit of the keywords and building blocks, otherwise the code can get a little overwhelming. So let’s go over them quickly once and we’ll re-cover this in the code again.
To understand the following clearly, remember:
1. Coroutines are like light-weight threads mapped to actual threads being executed.
2. Coroutines can launch other child coroutines and wait on their results.
Dispatcher
- Encapsulates the thread or the thread pool on which coroutine will execute.
- For e.g. For coroutine C, we want it start on a background thread dedicated to IO operations. For C5 we’ll want a DB thread.
- Some dispatchers are already provided by the coroutine library:
Main (thread) , IO (thread pool) , Default (thread pool) etc. - We can make out own dispatcher by wrapping a single thread or thread pool.
Coroutine job
- Represents a single coroutine task e.g. C or C1 etc.
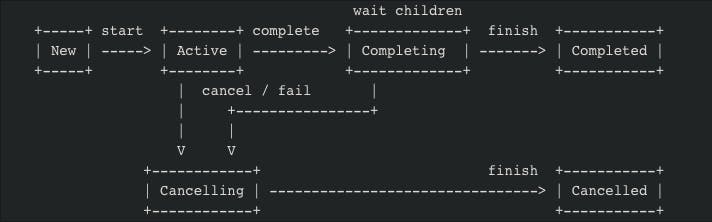
- It has a lifecycle with states (Imitating thread states)
- States : New, Active, Completing, Cancelling, Cancelled, Completed
- Any parent job like will only complete if all it’s child jobs are completed (or cancelled).
- C can only completed or be cancelled if all C1, C2, C3, C4, C5 are completed or cancelled.
- This imitates the parent-child relationship of process in OS world.
Coroutine start
- Tells the library whether we want to start the coroutine as soon as we declare or call it or lazily when asked to later.
Coroutine context
- A key value map of stuff most important for a coroutine like it’s dispatcher, the scope it’s running in, it’s start object, it’s job etc.
- When a child coroutine is started inside a parent one, it mixes it’s own context (usually empty coroutine context) with the one of the parent
- For e.g. C5 when launched will mix C’s context with whatever it’s own context is.
- Suppose C was running on Dispatchers.IO but C5 has to run on DB threads. So we’ll pass CustomDispathers.DB to C5 when launching. The libary will mix the contexts and the CustomDispathers.DB will take priority over Dispatchers.IO

Coroutine scope
- Scope in which a coroutine runs (similar to variable scope). When the scope ends, so does the coroutine.
- When a child coroutine is started inside a parent one it inherits parent scope (Unless specified otherwise). It means that when parent coroutine is stopped, so will the child coroutine since it’s scope was that of the parent.
- Global scope is provided by the library and lives throughout until the app is living. Coroutines launched on global scope run like daemon threads, they can’t stop the app from exiting.
- In android, there are ways to create scope that can be tied to activity, fragment or manual management.
Coroutine builders
- Builders provided by library to build coroutines around coroutine scopes.
- launch, async, runBlocking are some of the builders given by library
- They can add their own context to child builders launched inside.
- launch is used to do fire and forget things. It returns immediately when called returning the coroutine job.
- async also returns immediately and it returns a special kind of job called Deferred which can be cancelled or it’s result can be awaited.
- runBlocking is used to run tasks by blocking whichever thread it’s called on until the block completes.
- We’ll look into example soon to understand these builders better.
suspend keyword
- suspend keyword is applicable to functions.
- suspend means it may suspend the execution of the current coroutine i.e. saving the function stack frame and execute this function now. It doesn’t necessarily mean that the coroutine be changed.
- Let’s take an example:
Explanation:
Here as n1() is called inside coroutineX, it’s same as calling a normal f().
But when n2() is called from coroutineX, since n2() launches coroutineY, the calling coroutine, coroutineX is suspended and the thread it was executing on is returned to it’s Dispatchers.Default. Here the f() stack of coroutineX is saved.
When n2() returns the result then coroutineX is resumed from the stack and it executes on either the same or a new thread from Dispatchers.Default thread pool.
Note: Dispatchers gaurentee that the coroutine will run on a thread from the pool when they resume their suspension but doesn’t guarentee same thread execution. Usually we don’t care but if one has the use case, coroutines do provide ways to share thread local data between execution on different threads on a Dispatcher.
delay keyword
- It is like sleep for threads. It’s a suspend function which suspends the calling coroutine for the time period mentioned
Enough talk — Show me the code
Here is the solution for the task T using coroutines. The analysis is done in comments in the code.
We’ll look what task we are doing, the coroutine we are launching, the thread we are on, whether the operation will suspend the calling function, the scope we use, why we choose a particular coroutine builder, coroutine start context item and how jobs are represented and their end points.
Alright, let’s see the code.
Let’s see the f() for T1, T2 and T3 first.
Why async builder was chosen for T5?
I’ll explain in the following code but see if you can piece it together as well.
Now we see how the creation of coroutine C.
We launch in global scope to keep the example simple.
Now we have to do the tasks one by one. Check the code comments below for detailed explanation on what was done and why.
Until now we have started all our tasks inside C. Now we have to combine the result of all tasks.
Here is the final code for task T
Here is the main() calling T and waiting for it’s result.
Running the above code will give you a result matching to the following :
Starting C on DefaultDispatcher-worker-1
Inside t1() on DefaultDispatcher-worker-1
Starting task T2,T3 on DefaultDispatcher-worker-1
Starting task T4,T5 on DefaultDispatcher-worker-1
Inside Task T2,T3 on DefaultDispatcher-worker-3
Inside t2() on DefaultDispatcher-worker-3
Going to await result of task T2,T3 and T4,T5
Inside t3() on DefaultDispatcher-worker-1
Inside Task T4,T5 on DefaultDispatcher-worker-4
Inside t4() on DefaultDispatcher-worker-4
Inside t5() on pool-1-thread-1
The final result is 1_resultT2_resultT3_resultT4_resultT5
(Note: Task t4, t5 doesn’t start until we call await on it. That's because we used lazy coroutine start on it)
Now you should have an understanding of all the basic keywords and building blocks.
The line Coroutines are suspendible execution blocks should make sense now. They are execution blocks which might suspend the calling block but won’t block the thread from which they are called.
The code shown above is available on this github repo:
https://github.com/GauravChaddha1996/DeepDiveIntoCoroutine
Further reading
I’ve written posts on practical concepts for coroutines where I cover the concepts needed to use coroutines in actual projects, different use-cases that arise, while showing the code in action to explain the concepts clearly.